
Almost every company is today making a massive bet, either knowingly or unknowingly.
Tech companies are still aiming to spend as much as possible on tokens, so much it’s earned the term “tokenmaxxing”. And while betting against most of Silicon Valley is often a bad bet, we think most have gotten it wrong.
Jensen Huang famously said he'd be "deeply alarmed" if a $500K-a-year engineer didn't burn at least $250K in tokens. If you listen to him talk further, you’d know that he also talks about the need for measuring AI on its ROI in terms of "productive output per dollar of inference", in other words... not just tokenmaxxxing. The need for AI usage and innovation is real in most companies. History shows us pretty clearly that the firms that hesitate will die, be it Kodak on digital or Blockbuster on streaming. Amazon, by contrast, swallowed years of thin margins to build AWS before anyone else, turning a cost center into the most profitable part of their business. Even non-lethal examples like Facebook hesitating on mobile (instead betting on HTML5) cost them in ways we can only imagine.
On the flip side, the potential for misinterpretation of the $250k expectation when taken out of context is potentially life threatening for many companies. In these early days of the AI revolution, many companies have embraced tokenmaxxxing, some even more extremely so. AI leaderboards at Meta and JP Morgan celebrated the employees that spent the most tokens while others simply assumed per-seat cost and eventually metered cost would rise somewhat predictably.
But the days of tokenmaxxxing are quickly fading as agentic workflows and metered pricing enter the picture.
The fixed per-seat model is proving unsustainable for AI model providers, with agentic usage scaling faster than anyone ever predicted. And this is still the very early days of agentic AI. The newest best practice of agentic loops recently familiarized by Boris Cherny of Claude Code fame creates extreme leverage, and along with it, extreme risk. Currently, most agentic AI is within the product or at least within the R&D team. Most of it isn’t yet a scaled system of loops. Soon enough, though, this will become the norm not just in R&D, but in every team from marketing to legal. Microsoft and Uber have responded quite publicly by cutting or limiting spend. Microsoft cut most Claude Code licenses about six months after rolling them out, moving engineers to a cheaper internal path. Uber capped engineers at $1,500 (per tool per month) after torching its entire 2026 AI coding budget in just a few months.
If all AI spend were productive, this would be a different story. But we know that not to be the case, with a recent MIT study finding that roughly 95% of enterprise GenAI pilots delivered no measurable P&L impact at all.
These decisions to cut or cap spend, while logical at the outset, have major ramifications for the future. And most companies, including yours, are facing the exact same decision. Namely: how do you balance the need for AI innovation without spending yourself bankrupt.
Every company is making a bet on AI spend right now, and most of them are making it by accident. The bet hides inside thousands of small decisions, both made and yet to be made, that add up to a posture which nobody actually chose. Which model an engineer reaches for, whether an agent is allowed to loop, whether anyone capped the dev environment, who owns AI spend management, and a seemingly endless list of decisions that we all have done our best to make in a fast-changing environment.
Before dismissing this as a budgeting exercise, I think it’s worth stating that the stakes here are not just a FinOps or DevOps problem, but a strategic question that can determine much of your company's future in a world with AI. While we don’t profess to have a clear solution, we believe there is a logical approach here. The main positions we’ll argue are:
- Nuance is the answer. Both extremes (tokenmaxxxing and generic caps) are the wrong approach for most companies.
- Limiting teams to a just a few models or tools is a trap. You think you’re simplifying, but a lot of the value in AI comes from experimentation at the individual level. You need to leave room for open experimentation. (note, this may be fine as a stopgap solution to plug an Uber-sized budget drain & even a longer term solution for many use cases)
- Avoiding this decision is a decision (that you’ll regret). This means you’re just leaving it up to every individual in your company. This means that they’ll often use the most advanced models, a myriad of tools, and spin up endless agents, creating a mess that your 2086 hires will still be cleaning up.
- Making a decision that you don’t revisit often is just as bad as avoiding it. Ongoing measurement and optimization is required - you won’t answer this question today or in a year. You’ll need to continuously monitor and improve your approach, considering both internal and external factors.
Why the call is genuinely hard
Start with the trap that makes every projection lie to you. Per-token prices are in freefall. Gartner expects inference costs to drop over 90% by 2030. Yet bills climb anyway, with Goldman Sachs projecting that agentic AI will drive roughly a 24x rise in token consumption over the same period. Cheaper tokens don't shrink the bill; they make it economical to point AI at work you'd never have touched, so consumption outruns deflation. "The models are getting cheaper, so our costs will fall" is perhaps the most expensive assumption a leader can hold this year. It's true about the unit and false about the bill.
Underneath that is the structural shift: AI turned software from a largely high-margin asset into a metered consumable whose bill is written by behaviors like model choice, verbosity, reasoning depth, agent recursion, and how hard people lean on it. The variable costs of software were previously quite limited but at least in the early days of AI, that is changing.
Two numbers make the unpredictability concrete:
- Output and input matters: the spread between models for the same task is enormous, and output tokens cost 5–6x input.
- Model selection matters far more: The cost difference between flagship to budget is anywhere from 50-75x. The dangers of leveraging DeepSeek are slowly outweighed for many by the benefits of saving so much.
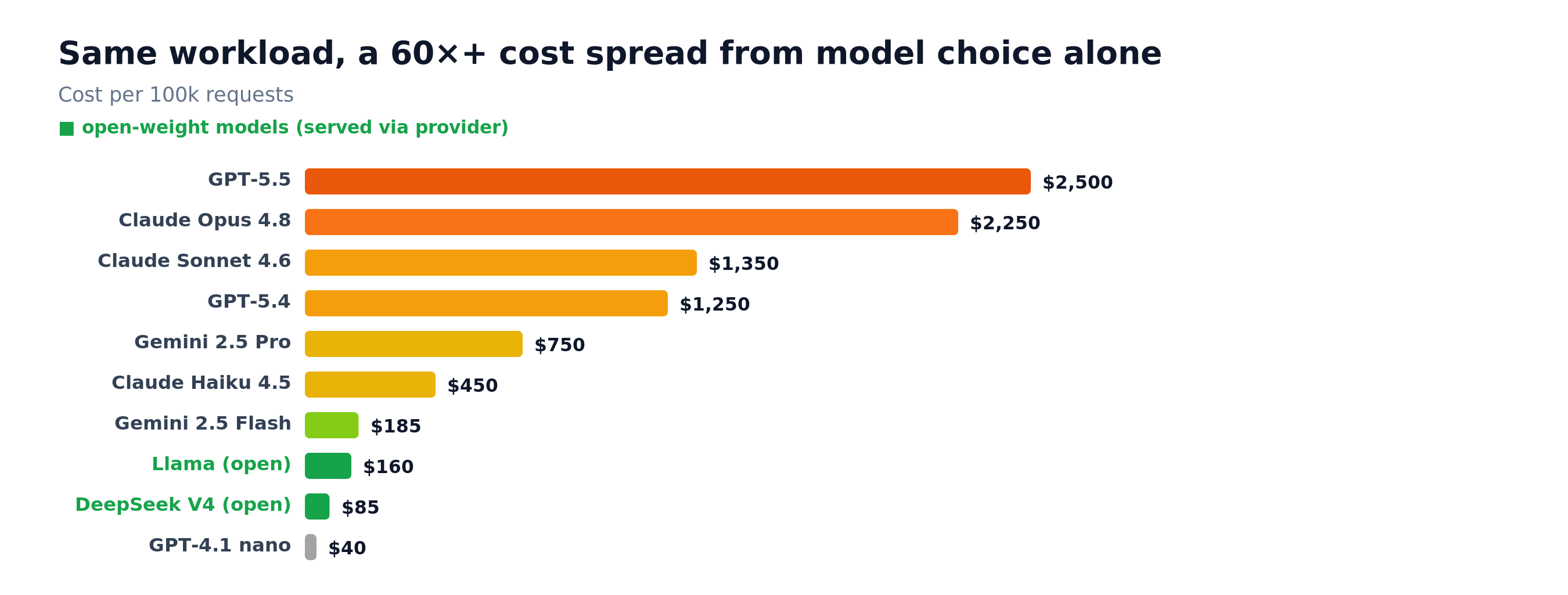
How you use agents affects the bill even more than model choice. The same user-facing task runs at wildly different cost depending on how the system is built:
Agentic cost scales quadratically, not linearly, with the number of interactions. ByteDance research, via Campbell Robertson, found that "token consumption grows quadratically with the number of API interactions… The meter doesn't just run. It accelerates." Because each step re-sends the entire accumulated context, you frequently can't predict what a complex agent task will cost until after it runs. Even worse, quadrupling is likely optimistic if you start to let agentic loops create their own agentic loops.
And the API invoice is only the visible tip. As Thesis Rationale put it, the complete cost chain of a deployed AI token, from chip depreciation through energy through inference infrastructure through human verification, is typically two to four times the visible API cost. Break the true bill into layers and the point becomes actionable; the layer you watch is rarely the one that's bleeding.
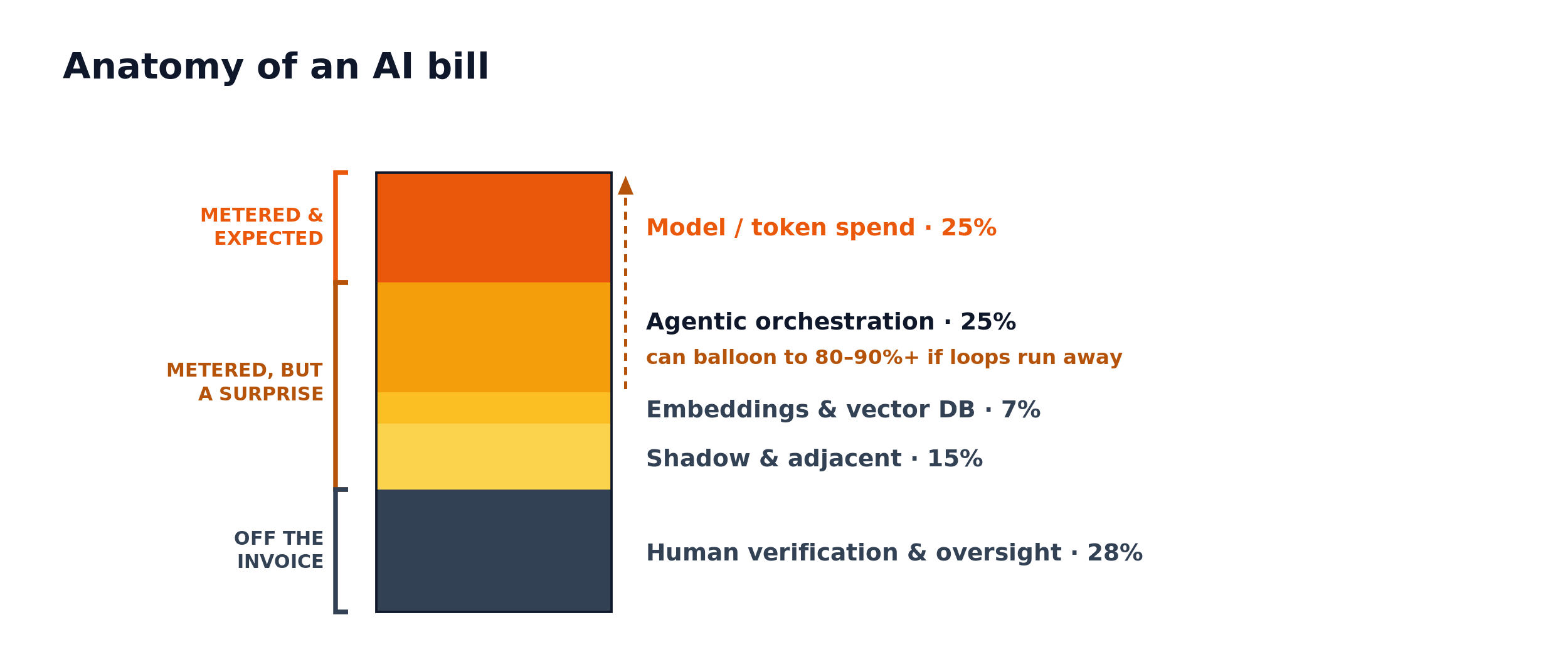
And the surprise costs still coming
Most of these costs are all but impossible to forecast. While only human oversight and self-hosted GPU time are truly off-invoice, the others are largely unbudgeted, unattributed, and in the case of orchestration, far larger than any linear estimate would suggest. When the largest cost layers are the invisible ones and the bill accelerates on its own, you can see why "should we spend more or less?" has no clean answer in the abstract. It depends on the bet.
Complicating matters further, none of this is static. The only certainty is that everything is going to keep changing very fast. Three more layers are forming on the right edge of that chart that most budgets don’t carry:
- Verification and verification of the verification. Human verification is quietly far more expensive than predicted, with Thesis Rationale putting oversight for a serious agent deployment at roughly $23,000 per agent per year, alongside a Forrester estimate of $14,200 per employee per year on hallucination mitigation. As oversight becomes the dominant cost in high-stakes work, companies are turning to models that check other models (verifier or critic models) to cut the human bill. That adds its own token spend you now pay to generate and to check. And in regulated domains it recurses: who watches the watchmen? Expect trust to become an explicit, growing line item, and a major new inference use case in its own right.
- Model provenance and audit. Once the model decision affects accuracy, bias, and data residency, regulators, auditors, and litigants will demand a per-decision record of which model, which version, on what data produced a given output. Capturing and retaining that provenance across every model you route to becomes a compliance cost that doesn't exist today.
- Evaluating model-task fit and experimentation. It won’t be obvious which tasks are right for which models. You’ll need to test and optimize this over time, per task. As new models are released, your teams gain more knowledge, and learning compounds, the formula is likely to shift often. The only way to make sure of this is leaving aside spend without a clear purpose, likely across every department and individual.
- The rise of self-hosting and system engineer hiring. While this is only for the largest enterprises with fixed spend, many companies will be enticed by the long-term benefits of avoiding inference costs and optimizing long term costs of clear AI use cases by building capabilities in-house. Almost all of these will inevitably fail after ballooning costs across the org.
- SaaS following suit with metered cost. SaaS margins are dropping with AI usage, and especially in the case of software whose customers can leverage agents within the current package, expect these costs to be passed on back to you. Expect Salesforce, Atlassian, Adobe, and others to expand their metered costs as their AI offerings get leveraged further. It’s hard to say where or how, but with every SaaS company releasing AI functionality either directly to the customer or under the hood, your bills will only grow. While I don’t think we’re seeing the end of per-seat pricing, many of the tools your org relies on are likely to adopt metered pricing.
- The subsidy unwind (the biggest one). Today's bills are propped up by frontier labs mostly selling below cost to win share. Just today when testing Claude’s new model, I saw their “2x usage promotion” for 5.0, which is even more heavily subsidized than everything prior. Some companies still haven’t moded past projecting prices per seat! When the public market starts pressuring them enough and capital tightens, prices will reset upward. The metered-billing shifts at Claude and GitHub Copilot were just the first tremors. Companies essentially are carrying a hidden liability of repaying the cost of this subsidy when the OpenAI’s of the world decide to go profitable. The prudent ones are already stress-testing their economics against a 2–3x price increase.
How companies are actually playing it
The useful signal isn't in analyst decks; it's in the postures real operators have already chosen.
1. Tokens are leverage, so spend more. Tokenmaxxxing isn’t really dead even if I believe it should be. Many companies are taking the risk that there is no time for optimization when technology is enabling so much innovation. This could result in massive returns for a lucky few, but will inevitably mean the end of many companies that are writing checks their tush (and their investor’s tushes) can’t cash. The bet: the real winners are the ones that bet on AI limitlessly.
2. Scale hard, optimize in place. Brian Armstrong says Coinbase is holding costs roughly flat even as token usage grows exponentially by routing prompts to the cheapest commercial model that clears the bar. “40% of daily code written at Coinbase is AI-generated. I want to get it to over 50% by October”, said Armstrong. The bet: AI is core, so scale it hard; just don't overpay per task.
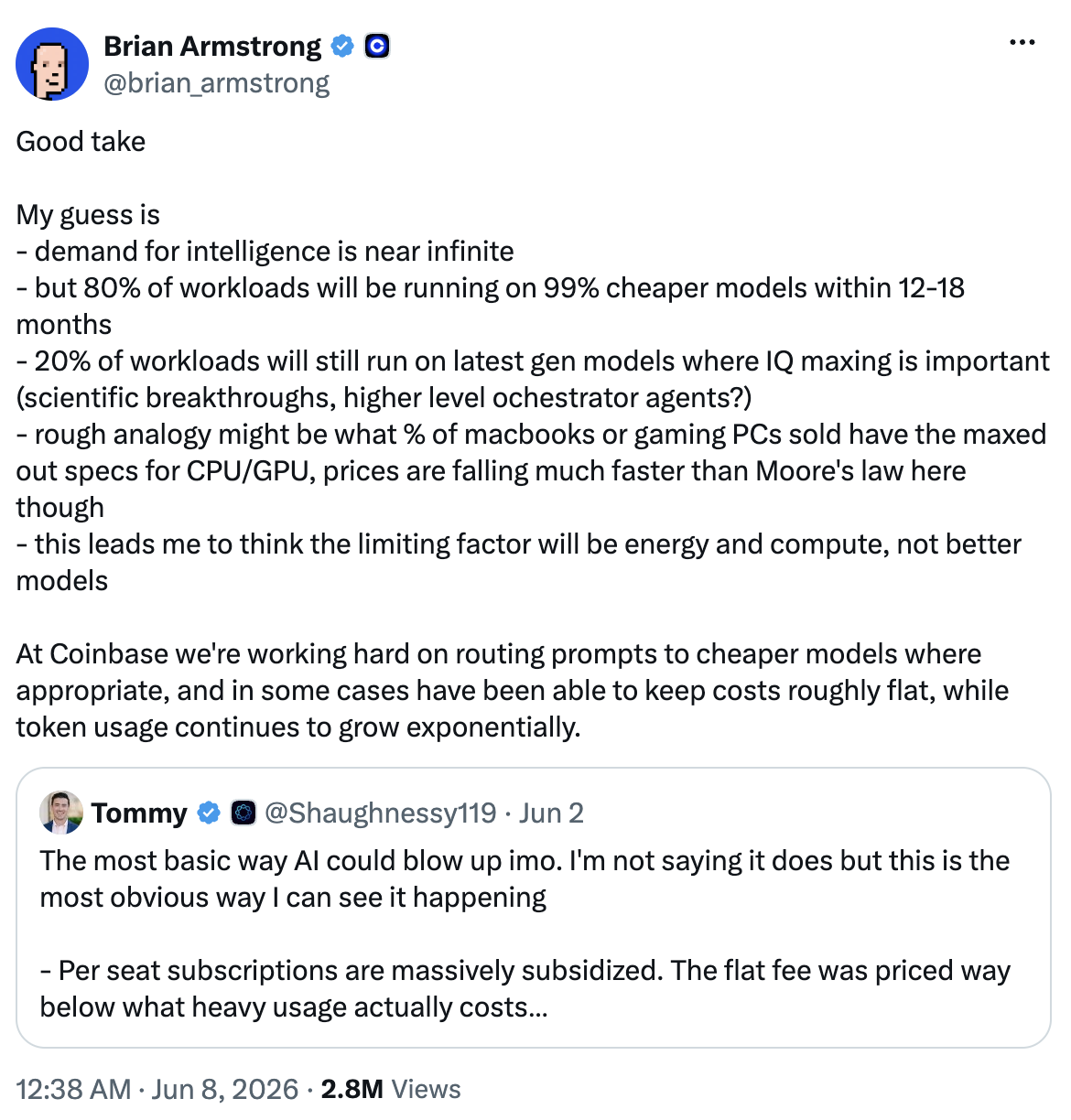
In reality, however, this is far easier said than done. It may keep costs down, but the tech for dynamically choosing the cheapest model for each task doesn’t really exist yet. In theory, this is great. In practice, it’s quite impractical.
3. Escape the pricing model entirely. A more radical posture: stop renting frontier models at all. Tunguz migrated a workload to an open-source model "over a weekend" and hit quality parity "at 12% of the cost." Tom Shaughnessy of Delphi argues this is the structural endgame. That flat per-seat pricing was always a subsidy as serious use forces you onto the metered API. Cheap open models, on the other hand, cap what the frontier labs can charge. The bet: your cost base is itself a choice, not a given.
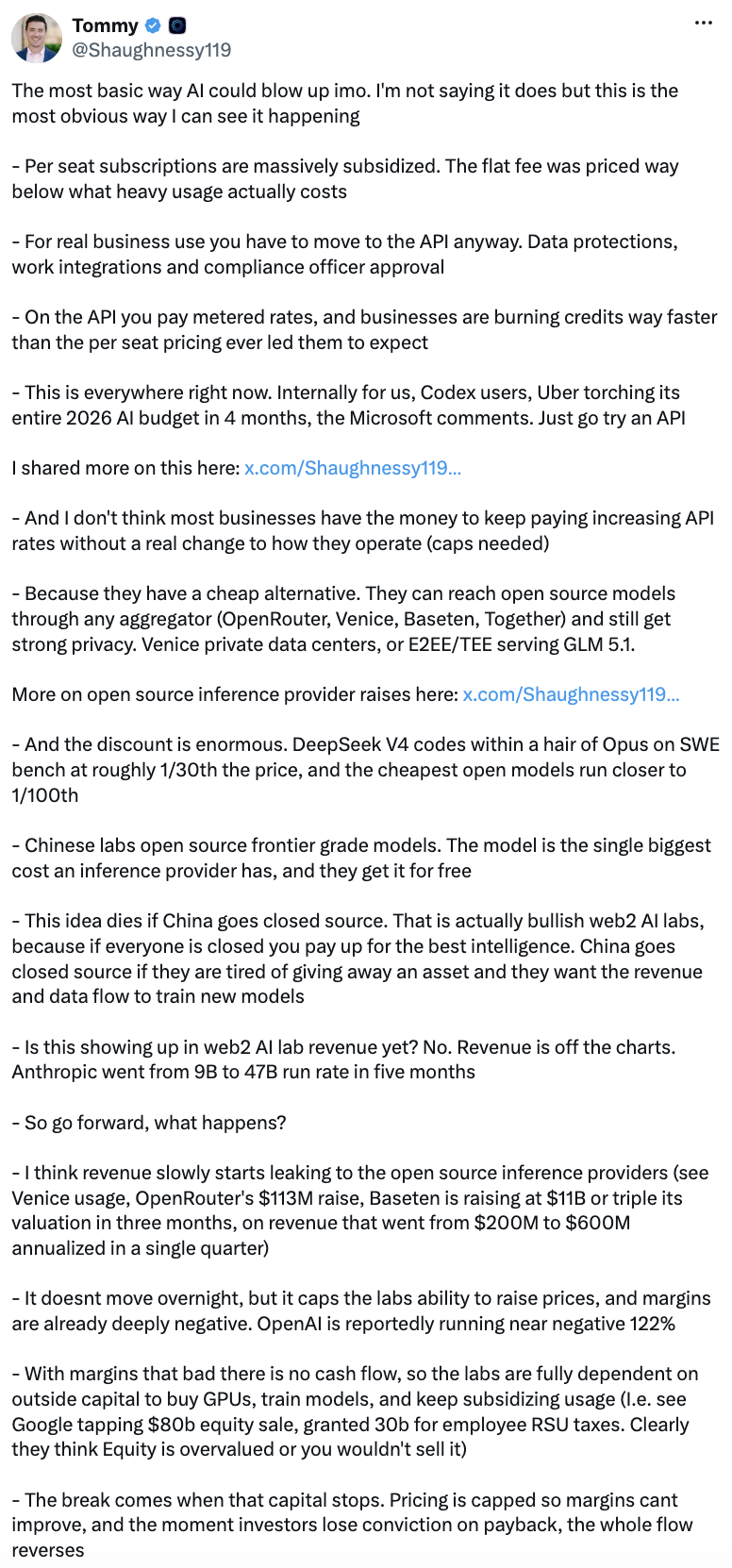
Disclaimer: we’ll get into this below but we think this is almost always a mistake. Open-sourcing and building in-house is almost inevitably going to end the way it did in cloud, with companies realizing that they simply can’t keep up with the leading providers.
4. Cut and cap usage. Microsoft and Uber were the first to do so publicly, as discussed above. But many others are joining in and will continue to. This may be a fine approach to slow things down in the short-term, but in the long-term, it may prove akin to betting against AI. Bet: AI is a cost like any other.
These aren't just different cost-control tactics; they're different bets about how central AI is to the company's edge. The mistake is reading them as a menu of equivalent options. They're not equivalent. Each may be right for different situations and the job is knowing which situation you're in.
The barbell: be extreme where it counts, disciplined everywhere else
The right answer is rarely generic limits or encouraging endless spend. It's a barbell. Be genuinely aggressive, Huang-style, on the bets where AI could redefine your competitive position or where being late is existential. Do the same where AI is clearly a cost saver (data entry, customer support, etc.). Be disciplined everywhere else, where AI is a useful tool and unbounded spend is simply waste. The losing move is the mushy middle, where you spread a moderate budget evenly across everything, which neither wins the bets that matter nor controls the leakage that doesn't. A big part of this also means designing agentic workflows intelligently. We’ll touch on that in more detail below.
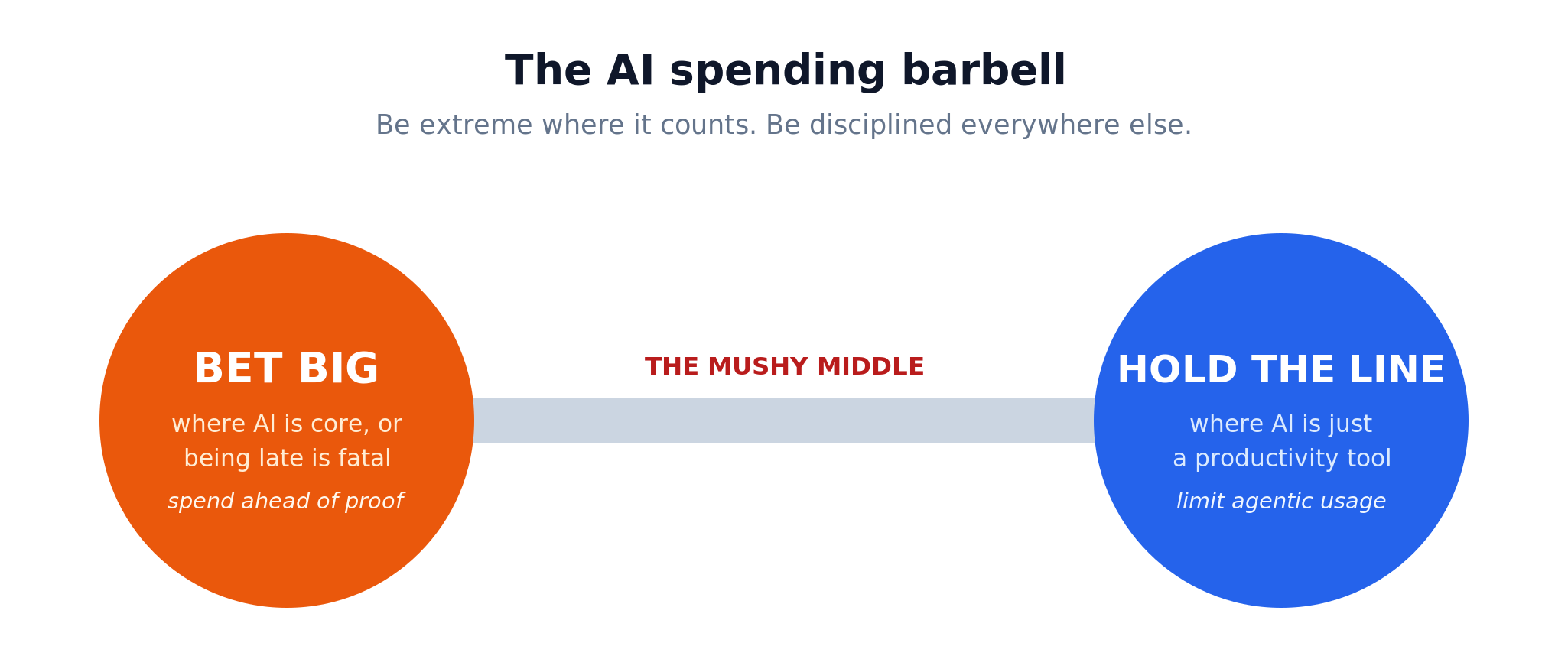
The reason most companies land in that middle is that they can't tell the two categories apart. So make the distinction explicit, on two questions:
- Is this a platform shift for our business, or a productivity tool? If AI changes what your product is or how your industry competes, and arriving late means arriving dead; you are in Blockbuster’s late 90s position. Spend ahead of proof, tolerate inefficiency, and optimize later, because the prize is survival, not margin. But if AI is only making your existing work faster and cheaper, it's a tool. Disciplined, ROI-gated spend wins, and "spend more on principle" is just margin you'll never get back.
- If it is a platform shift, can we actually win the bet? This is the survivorship-bias check, and it's where the seductive analogies mislead. For every Netflix and AWS, there's a graveyard of companies that "invested boldly" into oblivion. Amazon won because it had a real structural advantage and the balance sheet to outlast the thin-margin years. Blitzscaling logic only applies in a genuine winner-take-most land grab you have a credible shot at winning. Most internal AI usage is not that. It's opex, and pretending otherwise is how you get the half-billion-dollar Claude bill with nothing to show for it.
What’s the metric?
The metric that keeps the barbell honest isn't cost per token. And it isn’t clear what to measure or how to actually measure it. That said, the aim must be getting closer to ROI per token.
Robertson suggests segmenting how you think of costs. “The metric is not tokens per user. It is cost-per-useful-decision, cost-per-resolved-ticket, or cost-per-committed-code-line in production.” Imperfect, not quite ROI, but still far closer. Each department, team, and effort may require different AI metrics, but starting to enforce this method of thinking will prove valuable in the long run.
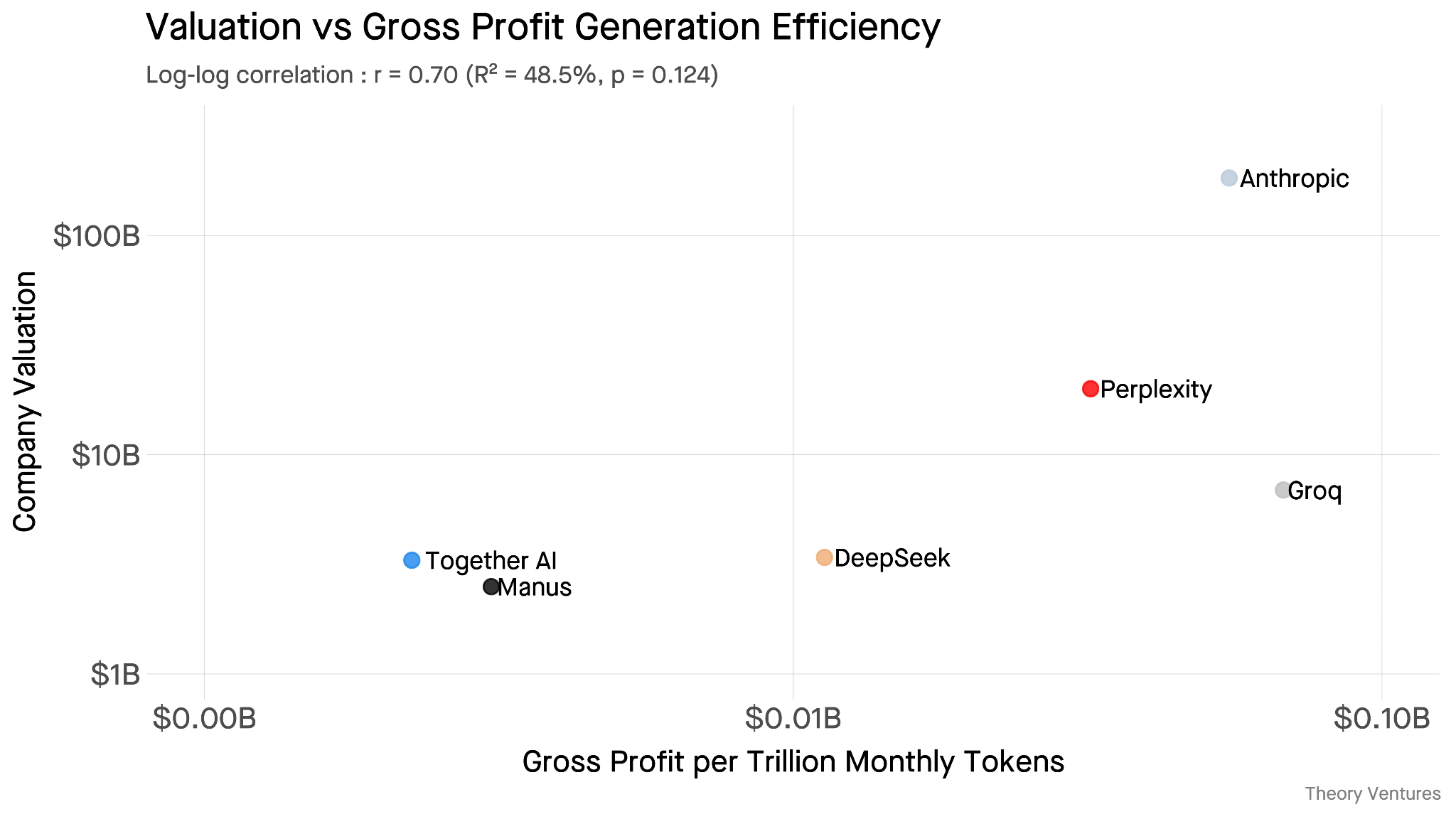
Some have started attempting to evaluate this across AI providers. Across Tunguz’s sample of six AI companies, gross profit per token correlated 0.70 with valuation while raw token volume correlated just 0.47. Both force the only question that resolves the spend debate: what did this money produce?
Executing the posture without bleeding
Once you know which arm of the barbell a given use case sits on, execution splits far more cleanly.
For the aggressive bets: spend big without waste, and without rationing your best people
The goal here is velocity, not frugality. Still, velocity isn't an excuse for stupidity. Two disciplines keep aggressive spend from becoming pure waste:
- Right-size the model per use case anyway. Even when you're spending freely, send classification and extraction to a budget model and reserve the flagship for genuine reasoning. The 50–75x flagship-to-budget spread should speak for itself. Most use cases don’t need the most expensive model.
- Don't ration the power users. The single biggest self-inflicted wound is a blunt per-seat cap that throttles exactly the people getting the most value . "Rationing prompts to stay under budget" makes the tool worse, which is what enraged developers when GitHub Copilot moved to metered token billing on June 1, 2026 and Pro+ subscribers burned their allowance in hours. Use smart limits instead: visibility into each person's own spend (Uber built exactly this dashboard, sharing that overspend often self-corrects when the meter is visible), generous caps with fast escalation, and smart routing defaults so cost falls without anyone feeling rationed.
For the disciplined majority: capture the easy savings
For everything that's a tool rather than a bet, the savings are mechanical, proven, and mostly unclaimed. Not because they're hard, but because nobody owns the question.
- Optimize by ROI first. Point spend where AI is an obvious winner: customer service at scale, document classification and data extraction, routine code review, translation at volume. Give those room to scale; cap the unproven experiments until they earn more
- Go cross-provider before you go exotic. You don't need open source or Chinese models to save real money. Tier down within one trusted provider (GPT-5.5 → GPT-5.4 → nano, or Opus → Sonnet → Haiku) for most of the routing savings with zero new vendors, then route across trusted Western providers (OpenAI, Anthropic, Google) for more. An AI gateway makes this operational.
- Limit usage of agentic flows and loops. Not every use case or department requires running agentic workflows or loops. Simply defining where it’s allowed can limit surprises
- Define agents or skills that guide token usage. Train agents to be cognizant of spend. It may even be worth running agentic flows to constantly look for places where tasks should not be token intensive.
Avoid the self-hosting trap
Self-hosting and open-weight models are the rungs most write-ups oversell. I’ve seen this before firsthand in cloud. Countless companies attempted to build their own private clouds. Despite throwing massive budgets at it, 0 succeeded. The same is proving to be true in the AI era. JP Morgan’s decision to self-host open-sourced AI is likely to be the first of many failures, with reports stating that their employees can’t even get an accurate summary of a document with an internal model that requires far more maintenance and high-end talent than any bank can afford.
The honest counter-argument deserves stating: Shaughnessy is likely right that open weights are the structural force capping the labs' pricing. But that disruption plays out across the industry; the cost and risk of acting on it land on your org, next quarter, ssnd they're steep. You inherit GPU provisioning and the idle-utilization trap (a GPU at 10% load makes per-token cost ~10x worse), security patching, scaling, and scarce MLOps talent at $150K–$300K+ each. Open weights are trained on undisclosed data, often trail proprietary leaders on instruction-following and judgment despite matching them on benchmarks, ship with fragile safety tuning and no SLA, and carry licensing ambiguity. The deepest optimizations need a serving team most companies can't hire. Tunguz's "weekend migration at 12% of cost" is real, but he had six months of task data to build test loops and is an unusually technical operator. For everyone else, a managed inference provider is the right path.
The tooling: the FinOps-for-AI market
This bring us to the companies aiming to solve this problem, which sorts into four camps best read by two questions; can it prevent spend or only report it & does it govern cost or risk?
- AI gateways (in-path, can prevent spend): Portkey, LiteLLM, TrueFoundry, Kong. The only category that can stop a cost before it happens. Free/open-source (LiteLLM) to a 1–3% managed premium.
- Pure AI-FinOps (report after the fact): CloudZero, Finout, Vantage, Apptio Cloudability. They ingest provider bills and allocate cost up the showback-then-chargeback ladder. Pricing from transparent self-serve (Vantage) to high-five-figure-plus enterprise contracts. Their structural limit is that you can't tag a token. An API call is a transaction, not an asset, so they reconstruct "who spent this" from keys and metadata, retrospectively, not from identity.
- AI governance suites (govern risk, not cost): IBM watsonx.governance, Credo AI, OneTrust, Holistic AI, and Collibra model inventory, risk, bias, regulatory mapping; costs range from ~$50K to several hundred thousand a year, largely silent on token economics.
- The hybrid: ServiceNow’s AI Control Tower which is responsible for a wide array here: discovery, observation, governance, security, and measurement, with cost and ROI dashboards. It’s powerful but heavy and oriented to the ServiceNow estate.
Worth noting is another category that often gets conflated with gateways, Inference providers (Baseten, Together, Fireworks, and the aggregator OpenRoute) run the models, serving open-weight models on optimized GPUs and billing for compute. They lower the unit cost of a token. AI gateways (Portkey, LiteLLM, TrueFoundry, Kong) don't run models; they sit in the request path and control which token gets spent and how many, via routing, caching, and per-key budget caps. You typically need both, and neither tells you who spent it or what data went out.
The gap across all five is the same: FinOps tools report cost but can't see human identity or content; gateways control spend but only for traffic you route through them, keyed on API keys, not people; governance suites watch risk but not tokens. None can say which person or agent ran up a bill, what data went out with it, and stop it in real time.
Where to start: the operating sequence
None of this requires a grand AI-cost strategy to begin. In fact, overplanning is an enemy of successful AI execution. It requires five steps:
- See everything, including shadow AI. You cannot manage what you cannot see, and a lot of the spend is invisible and unpredictable: agents, internal apps, and the unsanctioned tools employees expense on their own cards. Step zero is discovering every model, tool, and agent in use and metering spend per person, team, use case, and agent. Shadow AI isn't only a security gap; it's an unmeasured cost line. (And potentially, a live map of where AI is actually proving useful, but this is a point for another article) Pro tip: use AI to analyze the raw log you're seeing and let it suggest cost optimizations
- Attribute accountability. Spend with no owner never gets controlled. Tag every dollar to a team, feature, or customer, and give each function its own line. Start with showback (let people see their own usage) before chargeback (make them own it). Visibility alone self-corrects a surprising amount.
- Zone it and fund by conviction. Sort use cases onto the barbell: proven, core, high-fit work (data entry, extraction, support) earns near-unlimited budget; unproven or creative work gets a capped experiment budget, enough to learn and prove ROI. Benchmark each against what the task cost before AI.
- Control it with smart defaults and limits, not generic ones. Make the cheap path the default (routing, caching, output caps), set budgets and alerts, and put hard per-agent ceilings and circuit breakers on anything that can loop. Smart limits, not blunt per-seat caps that punish your best people driving innovation where it matters most.
- Design agentWhere to allow agentic flows and loops. Not every use case or department requires running agentic workflows or loops. Simply defining where it’s allowed can limit surprises
- Defining agents or skills that guide token usage. Train agents to be cognizant of spend. It may even be worth running agentic flows to constantly look for places where tasks should not be token intensive.
- Measure value. Start getting closer to measuring ROI. Start by tracking cost against the unit each function already contributes. This may be cost per resolved ticket, per processed record, or per closed deal. Measure at the zone level, not per token, so the number can't be gamed.
Done in order, these turn the strategy into an operating rhythm that you repeat as usage grows: see, attribute, zone, control, measure. Steps one and two are the foundation: every later step assumes you can already see and attribute the spend, which is exactly where most organizations are still blind.
The security stakes, briefly
Running the barbell with multiple models and providers expands your attack surface, and a few things matter most. More providers means more keys to leak and more places sensitive data lands. The models don't fail alike: a prompt-injection payload one vendor's filter neutralizes can sail through another's, so the routing you added to cut cost is itself a security event, silently changing which safety net catches a request. And agents raise the stakes from leak to loss. Since an agent takes actions and calls tools, an injection hidden in a document it reads can become real data exfiltration. These don't share one fix, but they share a need for a model-agnostic layer in the request path that inspects prompts and responses with identity attached and enforces consistent policy regardless of which model handled the call. The more you diversify to cut cost, the more you need it.
What it comes down to
While there will be outliers, most companies that win this era won't be either the cheapest or the most lavish. They'll be the ones who made the spend decision on purpose. Those who knew which of their AI bets could redefine the business and funded those past the point of comfort, and which were just tools to be held to a hard hard ROI line. That's the barbell, and the mushy middle loses to it in both directions. Under-spending on the bet that matters is how you miss opportunity. Overspending on the work that doesn't is how you join the 95% with nothing to show. Similarly thoughtless is ignoring the obvious fixes like model routing or going after the pipe dream that is self-hosting.
Cloud minted a new generation of giants and buried the incumbents who treated them as line items instead of fault lines. The AI cost structure is the next such sorting, and it is already under way. The companies that come out ahead will be the ones that treated the decision as what it is: not a budget to trim, but a bet on the future of their market. Volume is vanity. The first thing worth buying, in a world where the meter accelerates on its own, is the ability to see exactly where your money is going and what it's buying you, because you cannot make a bet this big on numbers you can't see.
Sources
- Gartner: inference >90% cheaper by 2030 - Gartner
- Goldman Sachs ~24x token consumption; agentic 5–30x per task - Fortune
- Jensen Huang "$250K in tokens" / Sam Altman "huge issue" - Tom's Hardware
- ~95% of GenAI pilots show no measurable P&L impact - MIT NANDA, via Fortune
- Brian Armstrong / Coinbase routing to cheaper models - The Block, X
- Uber spent its 2026 AI-coding budget in ~4 months; $1,500/engineer cap The Information, Fortune
- Microsoft pulled most Claude Code licenses - Fortune
- "Tokenmaxxing" + ByteDance quadratic-cost finding - Campbell Robertson, "Tokenmaxxing"; NYT, "More! More! More! Tech Workers Max Out Their A.I. Use" (Metz & Griffith, Mar 2026)
- Tomasz Tunguz: inference as compensation; gross profit per token - "Will I Be Paid in Tokens?", "Gross Profit per Token"
- Tom Shaughnessy (Delphi): per-seat subsidy / open-source escape valve - X
- Cost chain 2–4x; ~$23K/agent/yr oversight; where-AI-wins guidance - Thesis Rationale, "The AI Spending Trap"
- GitHub Copilot usage-based (token) billing, June 1, 2026 - GitHub Blog
- Model pricing (Claude, OpenAI, Gemini); 90% cache / 50% batch - Claude, OpenAI, Google AI
- Multi-agent ~15x tokens - Anthropic engineering, via ByteByteGo
- Open-weight model risks - Galileo, SitePoint
- AI margin compression; Casado "business gravity"; ICONIQ 52% vs 41% - SaaS Mag
- Providers vs. gateways (Baseten, Portkey, LiteLLM, TrueFoundry, Kong, OpenRouter) - TrueFoundry, Particula
- FinOps & governance market (CloudZero, Finout, Vantage, Apptio; watsonx.governance, Credo AI, OneTrust, Holistic AI, Collibra; ServiceNow AI Control Tower) - Amnic, ServiceNow, FinOps Foundation

.png)